ICCV 2025 | FDAM:告别模糊视界,源自电路理论的即插即用方法让视觉Transformer重获高清细节
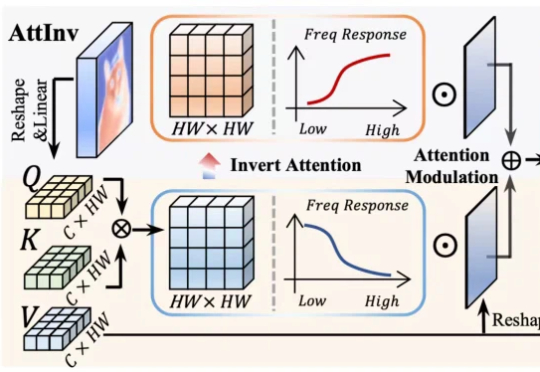
ICCV 2025 | FDAM:告别模糊视界,源自电路理论的即插即用方法让视觉Transformer重获高清细节针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。
来自主题: AI技术研报
7761 点击 2025-10-16 14:35